

RDA-Deutschland-Treffen 2016
Für das ZIMT in Siegen war auch das 3. RDA-Deutschland-Treffen Ende November wegen der nationalen, globalen Dateninfrastrukturen und dem vor dem Hintergrund des Aufbaus eigener Services von besonderem Interesse.
![]()
Es wurde vom Helmholtz Open Science Koordinationsbüro organisiert.
![]()
Die internationale Research Data Alliance hat 15 formale Empfehlungen entwickelt, die von mindestens 75 Organisationen adoptiert wurden. Themen der Veranstaltung waren Datenobjekte in zuverlässigen Repositorien, Verbesserung der Datenpraxis, um kosteneffektiver und effizienter zu sein. Ausserdem: Vermittlung von Forschungsdatenkompetenz.

Ein interessanter Vorschlag kam zu den Grundsätzen zum Umgang mit Forschungsdaten von 2010, diese auf den Stand von 2016 zu aktualisieren.
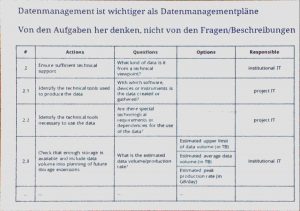
Wunsch: FDM-Infokompetenz-Schulung in Exzellenz-Strategie einbauen. Es gab Vorträge, Postersessions, Breakout-Sessions sowie Workshops und Trainingskurse. Auch Datenmanagementpläne wurden in mehreren Vorträgen thematisiert.
Ausserdem wurden Datenpublikationen, Metadatenschemata bis hin zu Linked Open Data diskutiert.

Aktualisiert um 15:43 am 1. Dezember 2016 von ge554
Teilnahme an MTSR 2016: 10th Anniversary Metadata and Semantics Research Conference
Ende November 2016 fand in Göttingen die 10. Internationale Konferenz zur Metadaten- und Semantikforschung (International Conference on Metadata and Semantics Research (theme: bridging the past, present and future of metadata) mit Teilnahme aus dem ZIMT, Siegen, statt. Sie wurde organisiert von Emmanouel Garoufallou vom „Alexander Technological Educational Institute of Thessaloniki“, Griechenland. Im Workshop zu den Digitalen Geisteswissenschaften und Langzeitarchivierung ging es zum Beispiel um Metadaten und Semantik sowie um Kollaboration der verschiedenen Communities, wie zum Beispiel Geschichte, digitale Geisteswissenschaften und Data Mining.
Die einzelnen Tracks kamen aus den folgenden Bereichen:
- Kulturellen Sammlungen und Anwendungen
- Landwirtschaft, Ernährung und Umwelt
- Digitale Bibliotheken, Informationsbeschaffung (Information Retrieval), Big, Linked & Social Data
- Europäische und nationale Projekte
- Offene Repositorien, Forschungsinformationssysteme und Dateninfrastrukturen
Vorgestellt wurde auch das Lemon-Modell (The Lexicon Model for Ontologies), ein Modell um auch maschinenlesbare Wörterbücher zu modellieren und sie mit dem Semantischen Web und der Linked Data Cloud zu verknüpfen.
Das MoRe Tool (Metadata & Object Repository) wurde präsentiert und erläutert, wie man Informationen aggregieren kann. Interessant war die Dokumentation zu CONTENTdm, dem digitalen „Collection Management System“, das aus einem Server besteht, auf dem Inhalte gespeichert werden können. Nutzer speichern Materialien auf OCLC Servern.
Vorgestellt wurden auch:
CIDOC Conceptual ReferenceModel, die Ontologie für Informationen aus dem Kulturerbe.
Aktualisiert um 11:37 am 1. Dezember 2016 von ge554